AI Digest, um resumo do que mais importante está a acontecer no campo da Inteligência Artificial

Robotáxis chineses: a IA com rodas e contas feitas
O detalhe importante está menos no robotáxi em si e mais no pacote industrial que o torna possível. A China está a tentar exportar uma combinação de hardware, sensores, computação, integração automóvel e cadeia de fornecimento com escala suficiente para esmagar custos. É aqui que a expressão “physical AI”, tantas vezes tratada como conceito vago, ganha um contorno mais concreto: máquinas que circulam, cobram, avariam, são reparadas e precisam de margens para lá da demonstração. O Ocidente continua a discutir segurança, regulação e aceitação pública, com bons motivos. Mas há uma diferença operacional que começa a pesar: quem consegue fabricar barato aprende mais depressa, porque consegue pôr mais unidades no terreno. Cada quilómetro recolhe dados, expõe falhas e aproxima o produto da viabilidade comercial. O futuro autónomo pode acabar por ser decidido por uma pergunta seca: quanto custa pôr isto na rua sem perder dinheiro? GPT-Rosalind: a IA entra no laboratório pela porta dos fluxos de trabalho
O sistema chega em acesso limitado, através de um programa para clientes qualificados, e pode ser usado no ChatGPT, no Codex e por API. Em paralelo, a OpenAI lançou um plugin gratuito de investigação em ciências da vida para o Codex, ligado a mais de 50 ferramentas e fontes de dados científicos. Entre os parceiros referidos estão Amgen, Moderna, Allen Institute, Thermo Fisher Scientific, NVIDIA, Benchling, Oracle Health and Life Sciences e a escola de farmácia da Universidade da Califórnia em São Francisco. A promessa é reduzir fricção numa fase especialmente cara da investigação. A própria OpenAI lembra que, nos Estados Unidos, uma terapêutica pode levar cerca de dez a 15 anos entre a descoberta do alvo e a aprovação regulatória. O GPT-Rosalind não encurta ensaios clínicos por memorando, nem transforma hipóteses em medicamentos por entusiasmo computacional. Pode, no entanto, ajudar a escolher melhores alvos, rever literatura, cruzar dados genéticos, moleculares e experimentais, sugerir experiências e chamar ferramentas especializadas sem obrigar o investigador a saltar entre sistemas mal integrados. A parte séria está aí. Em biologia, o funil costuma ser a dificuldade de distinguir uma hipótese elegante de uma hipótese testável. Se o GPT-Rosalind tiver utilidade, será nesse ponto menos vistoso: filtrar possibilidades antes de alguém gastar meses de laboratório, reagentes e orçamento numa linha de investigação fraca. A IA científica não ganha credibilidade por parecer mais eloquente. Ganha-a quando poupa más experiências. IA científica: menos resumos, mais mapas de hipótese
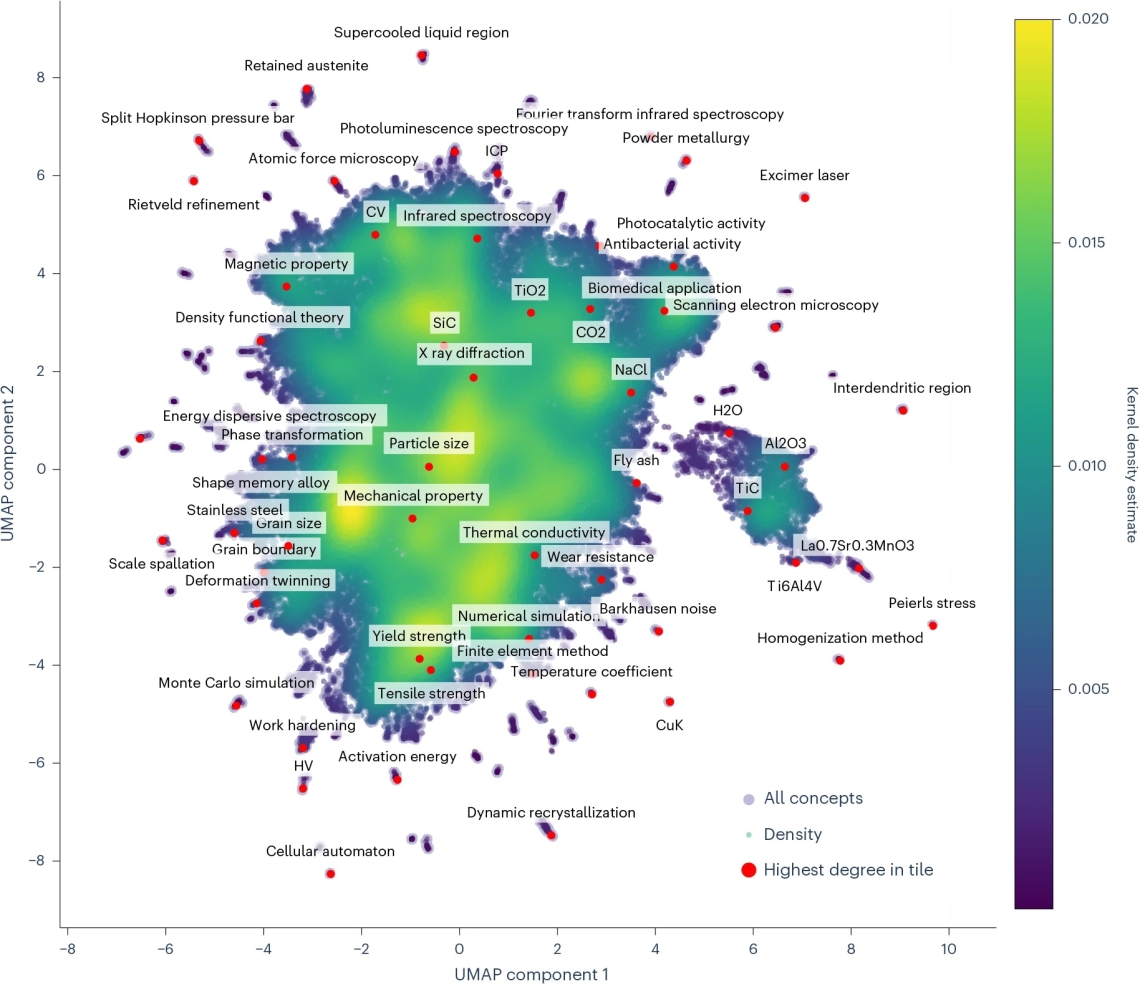
Um artigo publicado em abril na Nature Machine Intelligence testou um uso interessante e concreto dos grandes modelos de linguagem: transformar literatura de ciência dos materiais num mapa de ligações entre conceitos. A equipa recolheu artigos via OpenAlex, juntou títulos e resumos, extraiu fórmulas químicas em separado e afinou um modelo LLaMA-2-13B para identificar conceitos científicos relevantes. O modelo foi treinado com apenas 200 resumos anotados e depois aplicado a cerca de 221 mil resumos. A partir daí, cada conceito passou a ser um nó num grafo. Quando dois conceitos apareciam no mesmo resumo, criava-se uma ligação com data. O objetivo era usar a evolução histórica dessas ligações para prever combinações que ainda não tinham surgido, mas podiam aparecer nos anos seguintes. A melhor abordagem juntou uma rede neuronal de grafos com informação semântica extraída dos textos, e superou os métodos de referência na previsão dessas novas ligações, sobretudo nos cruzamentos menos óbvios. A validação humana foi pequena: dez especialistas receberam relatórios personalizados com combinações sugeridas pelo modelo. Os próprios autores reconhecem que a amostra é limitada e pode conter enviesamentos. Ainda assim, o trabalho aponta para uma aplicação útil: não pedir à IA que descubra materiais por decreto, mas que indique cruzamentos de literatura que merecem leitura e talvez laboratório. A parte séria está nesse estreitamento. Num campo saturado de publicações, o valor não está em mais um resumo automático com ar competente. Está em reduzir o custo de orientação: que combinações parecem próximas de se tornar investigáveis, quais repetem caminhos evidentes e quais podem justificar tempo humano antes de consumirem reagentes, bolsas e anos de doutoramento. |
Receba todas as novidades na sua caixa de correio!
 A China parece ter encontrado uma forma pragmática de acelerar a inteligência artificial física: baixar o preço por unidade. A WeRide anunciou, em parceria com a Lenovo, um plano para colocar cerca de 200 mil veículos autónomos nas estradas mundiais nos próximos cinco anos. Ao mesmo tempo, a Pony AI diz que a sua sétima geração de robotáxis já desceu para menos de 230 mil yuan por veículo, cerca de 29 mil euros, incluindo carro-base, bateria e kit de condução autónoma.
A China parece ter encontrado uma forma pragmática de acelerar a inteligência artificial física: baixar o preço por unidade. A WeRide anunciou, em parceria com a Lenovo, um plano para colocar cerca de 200 mil veículos autónomos nas estradas mundiais nos próximos cinco anos. Ao mesmo tempo, a Pony AI diz que a sua sétima geração de robotáxis já desceu para menos de 230 mil yuan por veículo, cerca de 29 mil euros, incluindo carro-base, bateria e kit de condução autónoma. A OpenAI apresentou em abril o GPT-Rosalind, um modelo de raciocínio feito para ciências da vida, descoberta de fármacos e passagem de resultados laboratoriais para aplicações clínicas. A escolha do nome aponta para Rosalind Franklin, mas o ponto relevante está menos na homenagem do que no desenho do produto: o modelo foi otimizado para química, engenharia de proteínas, genómica, interpretação de resultados experimentais e uso de bases de dados científicas.
A OpenAI apresentou em abril o GPT-Rosalind, um modelo de raciocínio feito para ciências da vida, descoberta de fármacos e passagem de resultados laboratoriais para aplicações clínicas. A escolha do nome aponta para Rosalind Franklin, mas o ponto relevante está menos na homenagem do que no desenho do produto: o modelo foi otimizado para química, engenharia de proteínas, genómica, interpretação de resultados experimentais e uso de bases de dados científicas.